./mcah run -d --debug gdb> r tests/html/about-mozilla.html ...blahblah
所以有在動啊……
./mach run -d tests/html/about-mozilla.html -o output.png 輸出圖檔,圖片也是一片白。
update 系統再 try 也不行。
用 VM LMDE 跑 pre-built 出現其他 error 0:1(10): error: GLSL 1.50 is not supported. Supported versions are 1.10, 1.20, 1.30, 1.00 ES, and 3.00 ES,可能跟 VM 沒 support OpenGL 有關,有點岔題所以不管。
最早遇到 MVC 是在網頁 framework,所以一直理解 model 為「資料」。後來發現 model 好像不只是資料,有文件說 model 包含商業邏輯,但我還是說不上來到底是什麼。現在的理解是絕大多數的程式都是 model,只是把 view 拆出去並且引進 controller 作為類似中介的角色。
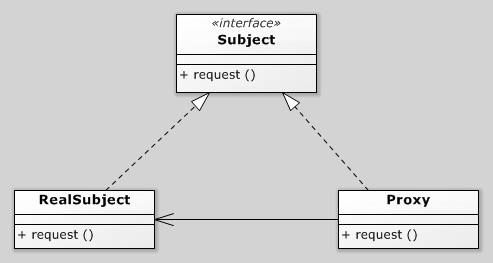
代理建立成本很高的 object,所謂成本很高可能是需要比較多時間等等,例如 video object 需要從網路抓影片、回應很慢的 API 等等。等待過程中但又不希望卡到 UI 操作,這時候就可以透過 virtual proxy 先回一個 loading 畫面,等到 video 抓好或 API 回來之後,就由真正的 object 做事。
系統中的 object 應該只跟它很有關係的 object 互動,不要讓太多 class 綁在一起,免得動一個就動到一大堆。動 A 會動到 B 往往是 bug 的來源……
設計時要注意物件所互動的 class 有哪些以及是如何互動的。
針對 interface 寫 code,不針對 implement 寫 code
想使用某一堆類似的 class 時,應該是讓這些 class 有個 interface 並透過 interface 使用 class,而不是針對特定某個 class 寫 code。如果針對 interface 寫 code,當 class 又增加時可以運用多型在一開始生新的 class 的 object,之後使用該 object 的 code 都可以不用改。
多用合成,少用繼承
「合成」像是把東西組起來,是「有」,has-a。「繼承」則是「是」,is-a。
這我還沒有很懂為什麼……只想到一個爛例子,如果 class A 需要某個功能,例如 parse json,假設已經有一個 json parser 的 class,那麼應該是讓 class A 以合成的方式使用 json parser,而不是去繼承 json parser。這個例子很明顯,用繼承會讓 class A 的語意變得很奇怪,不過不是每種狀況都那麼明顯……
list 繼承 __list_imp,所以 __link_nodes_at_front() 的 base::__end_ 是 __list_imp 的 __end_。從上面四個 function 看起來,__end_.__prev_ 指到 list 的最後一個 node,__end_.__next_ 指向 list 第一個 node。也就是說,__end_ 是用來記錄 list 的第一個及最後一個 node。
d-pointer 是個 design pattern,也叫 Opaque pointer 或 Pimpl idiom。它分開給外面看的公開 class interface 跟實作的 class。做法是在公開 class 放個實作 class 的 pointer,公開 class 各 function 只是 call implementation class 的 function。公開 class 中跟實作相關的 member 只有那個 pointer,所以 size 會固定是 pointer 的 size。老覺得在哪看過類似的東西……
Qt 用 d-pointer 主要是為了保持 binary compatibility。
Binary Compatibility
有 binary compatibility 表示 application 在以舊版 library compile 後,新版 library binary 可以直接取代舊版 library 而不需要重新 compile application。要達到 binary compatibility 就不能改變已經公開出去的 C++ class 的 size 或 memory layout,即不能增加 member 或者更改 function 跟 member 的順序。如果改了,application 認定的 library class size 或 memory layout 跟新版 library 不同,會把 memory 踩爛掉。
Qt 使用 d-pointer 達到不修改既有公開 class 還能增加 feature 或修改實作細節。
voidQStandardItemPrivate::setChild(int row, int column, QStandardItem *item, bool emitChanged) { Q_Q(QStandardItem); ... if (rows <= row) q->setRowCount(row + 1); ... }
透過 q_func() 拿到的 q 是轉型成 QStandardItem* 的 pointer。
這個例子裡,因為 QStandardItem 跟 QStandardItemPrivate 沒有繼承別人,它們自己分別記錄了 d_ptr 跟 q_ptr,所以 d_func() 跟 q_func() 有沒有轉型根本沒差。但其他繼承 QObjectPrivate 的 class,q_ptr 是從 QObjectData 來的,type 是 QObject*,如果要直接使用 sub class 的 member 就得轉型,d_ptr 同理。除非用 virtual function 做多型,不過這個狀況用 virtual function 很怪,因為這樣 base class QObject 得有所有 sub class 會用到的 interface,這邊顯然不是這個意思,用 virtual function 不合理。