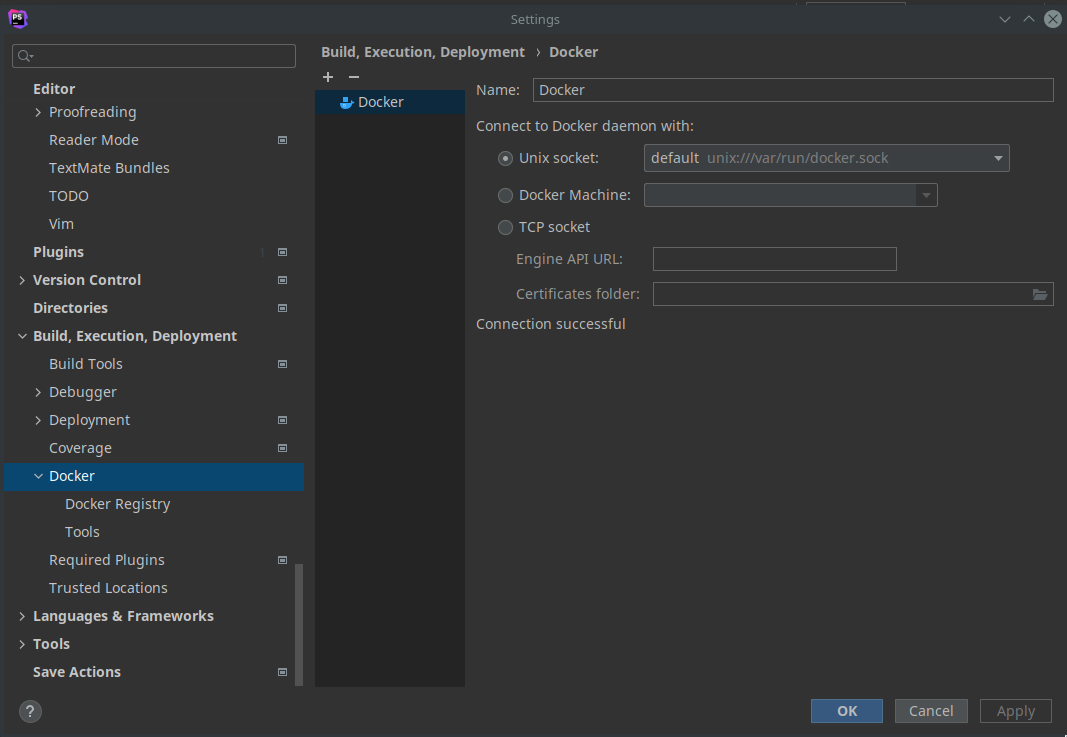
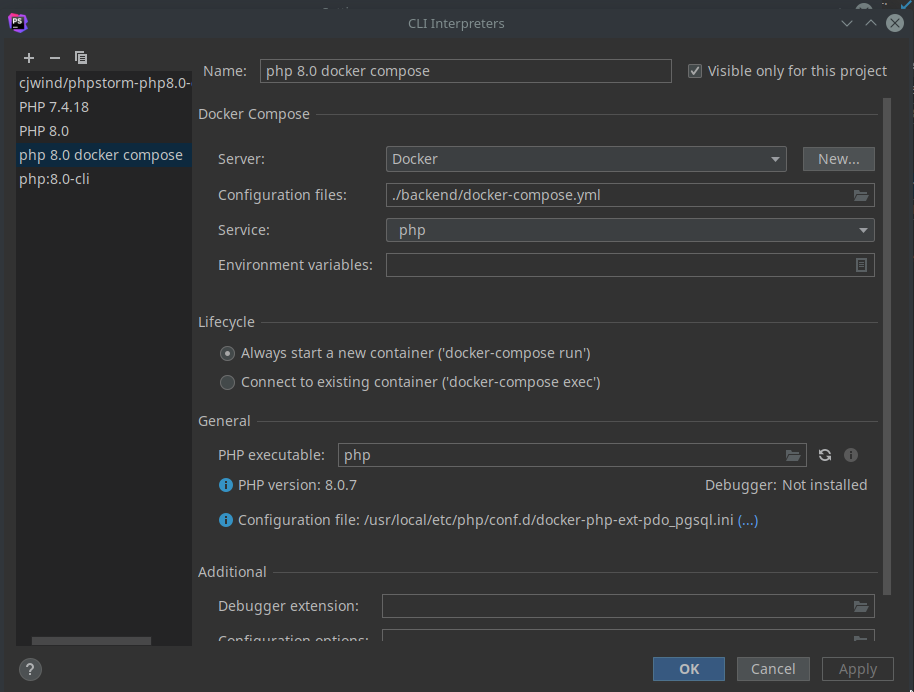
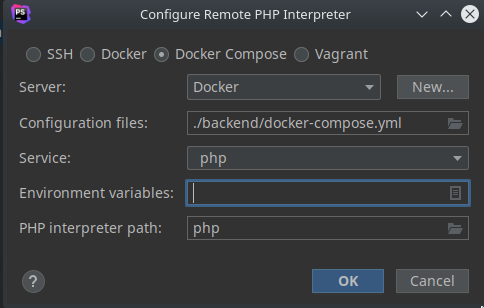
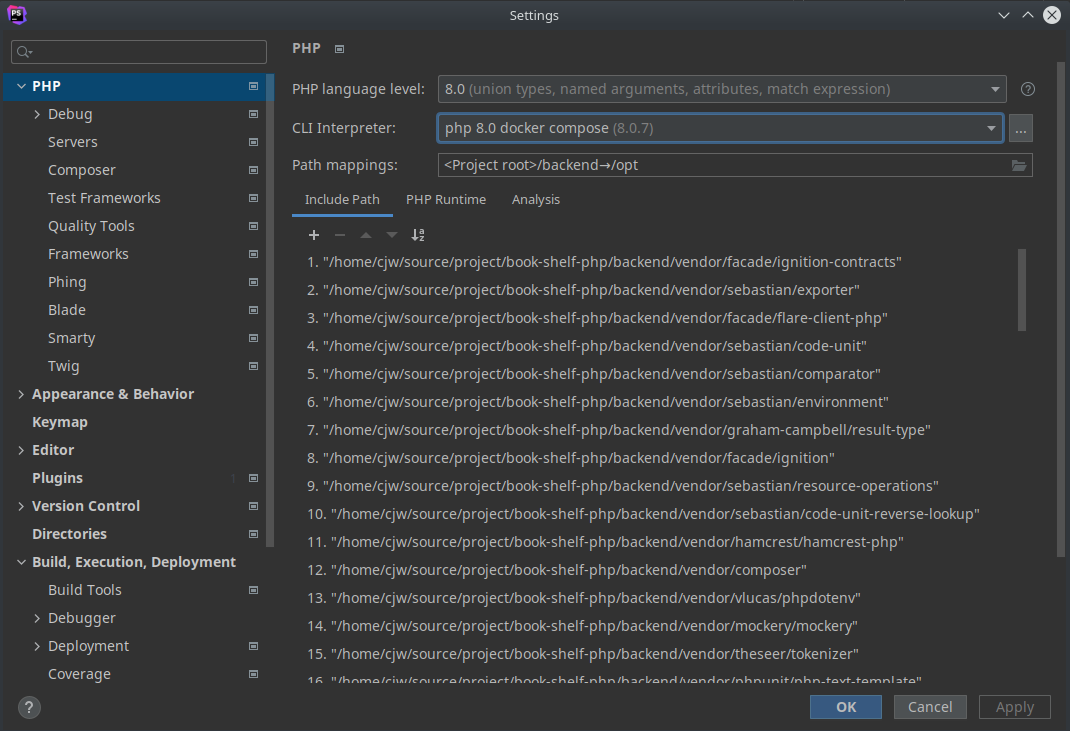
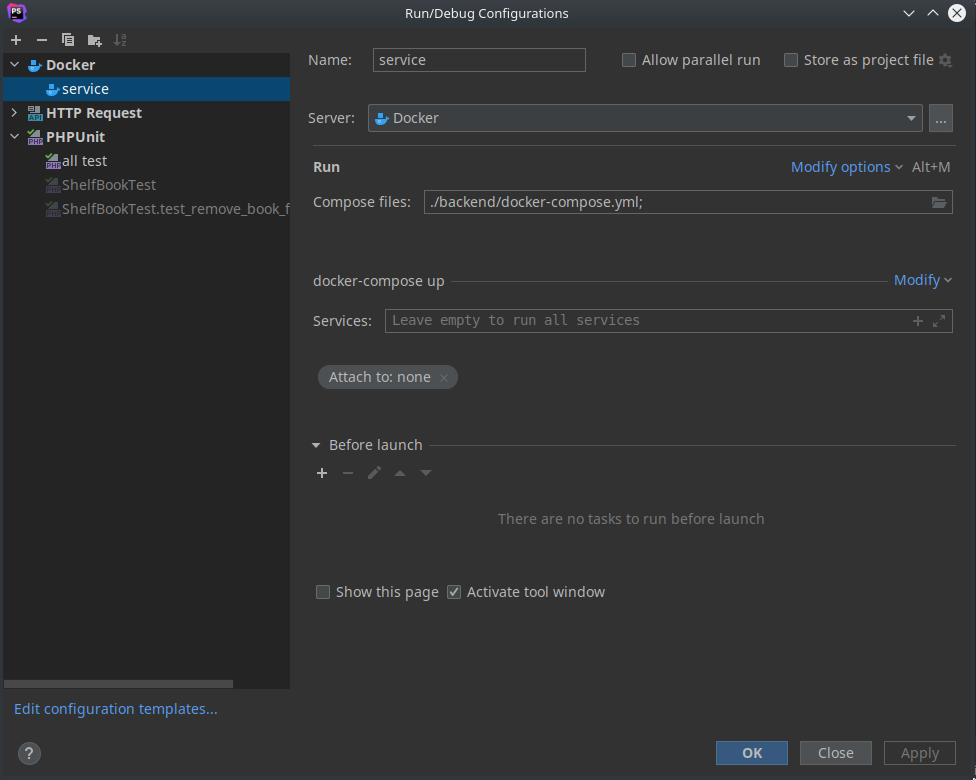
這樣我們就得到前面 function 的 raw machine code 了!來反組譯看看它的內容:
1 2 3 4 5 6 7 8
$ ndisasm -b 32 basic.bin
00000000 55 push ebp 00000001 89E5 mov ebp,esp 00000003 B8BABA0000 mov eax,0xbaba 00000008 5D pop ebp 00000009 C3 ret ...
可以看到進入 function 時會先 push ebp 到 stack 裡保存,等到 function 要 return 前恢復,這樣回到 caller 才不會搞亂 caller 的 register 內容。
接著將 esp 的值 assign 給 ebp,也就是將 stack base pointer 設定成目前 stack top 的位置,這麼做就是在原本的 stack 上再做出一個 stack 給目前這個 function 使用,這個動作是在為目前的 function 設定它的 stack frame。stack frame 裡會儲存 function 的 local variable。
setup 好 stack frame 後,0xbaba 被 assign 給 register eax,這是因為 register eax 是 C 語言用來放 return value 的 register,caller 會預期 callee 的 return value 會放在 eax。
Local Variables
接下來我們寫這樣一個 function:
1 2 3 4
int foo() { int x = 0xbaba; return x; }
將它 compile 成 raw binary 再反組譯,得到:
1 2 3 4 5 6 7
00000000 55 push ebp 00000001 89E5 mov ebp,esp ; setup stack frame, stack bottom = stack top 00000003 83EC10 sub esp,byte +0x10 ; allocate 16 bytes on the top of stack 00000006 C745FCBABA0000 mov dword [ebp-0x4],0xbaba ; 將資料存到 stack 上 0000000D 8B45FC mov eax,[ebp-0x4] ; 將 local variable 的值放進 eax 作為 return value 00000010 C9 leave ; restore stack for caller 00000011 C3 ret
一開始先在 stack 保存 ebp,接著 setup stack frame,再來由 sub esp,byte +0x10 在 stack top 保留 16 byte 的空間。但我們明明是要儲存 4 byte 的 int,為什麼需要保留 16 byte 呢?這是因為 CPU 在 memory 的 data 有對齊(alignment)的時候,會有比較好的效能,這是 CPU 最佳化的一個方式。所以雖然我們只要存 4 byte 的資料,但為了讓資料能對齊,會採用最大的 datatype width 16 byte 來放每個 stack 中的 element。dword 表示 double word,也就是 4 bytes。
最後的 leave 是用來恢復 stack 的,等同以下:
1 2
mov esp, ebp ; restore stack top pop ebp ; restore stack bottom
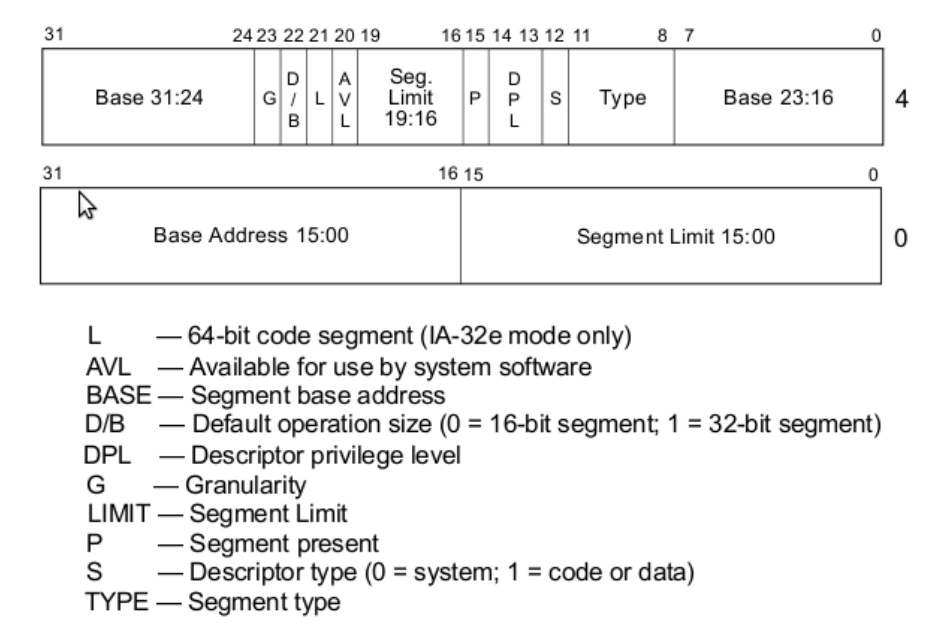
gdt_null: ; the mandatory null descriptor dd 0x0 ; dd means define double word (4 bytes) dd 0x0 gdt_code: ; the code segment descriptor ; base = 0x0, limit = 0xfffff ; 1st flags: (present)1 (privilege)00 (descriptor type)1 -> 1001b ; type flags: (code)1 (conforming)0 (readable)1 (accessed)0 -> 1010b ; 2nd flags: (granularity)1 (32-bit default)1 (64-bit seg)0 (AVL)0 -> 1100 dw 0xffff ; Limit (bits 0-15) dw 0x0 ; Base (bits 0-15) db 0x0 ; Base (bits 0-15) db 10011010b ; 1st flags, type flags db 11001111b ; 2nd flags, Limit (bits 16-19) db 0x0 ; Base (bits 24-31)
gdt_data: ; the data segment descriptor ; Same as code segment except for the type flags: ; type flags: (code)0 (expand down)0 (writable)1 (accessed)0 -> 0010b dw 0xffff ; Limit (bits 0-15) dw 0x0 ; Base (bits 0-15) db 0x0 ; Base (bits 0-15) db 10010010b ; 1st flags, type flags db 11001111b ; 2nd flags, Limit (bits 16-19) db 0x0 ; Base (bits 24-31)
gdt_end:
; GDT descriptor gdt_descriptor: dw gdt_end - gdt_start - 1 ; Size of GDT, always less one of the true size dd gdt_start ; Start address of GDT ; segment descriptor offset CODE_SEG equ gdt_code - gdt_start DATA_SEG equ gdt_data - gdt_start
在 text 模式下,我們只需要在一塊特定的 memory 裡指定我們要印的字元以及其 attribute 即可畫出一個字元。這塊 memory 從 0xb8000 開始,用兩個 bit 表示一個字元,第一個 bit 是要印字元的 ASCII code,第二個 bit 則是 attribute,例如顏色。
print_string: ; function name pusha ; push all register to stack to preserve them
mov ah, 0x0e ; tty mode
loop_start: cmp byte [bx], 0 ; compare [bx] which is one byte to zero, for null terminating char je loop_end ; if [bx] == 0, end loop mov al, [bx] ; move char printed to al int 0x10 ; call print interrupt add bx, 1 ; bx + 1, move to next char jmp loop_start ; run loop body again
loop_end: popa ; restore all register ret ; return to callee
; padding and magic number times 510-($-$$) db 0 dw 0xaa55
第四版:拆成多個檔案
print_string.asm:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
print_string: ; function name pusha ; push all register to stack to preserve them
mov ah, 0x0e ; tty mode
loop_start: cmp byte [bx], 0 ; compare [bx] which is one byte to zero, for null terminating char je loop_end ; if [bx] == 0, end loop mov al, [bx] ; move char printed to al int 0x10 ; call print interrupt add bx, 1 ; bx + 1, move to next char jmp loop_start ; run loop body again
loop_end: popa ; restore all register ret ; return to callee
; data HELLO_MSG: db 'Hello, World!', 0 GOODBYE_MSG: db 'Goodbye!', 0
; padding and magic number times 510-($-$$) db 0 dw 0xaa55
print_string.asm:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
print_string: ; function name pusha ; push all register to stack to preserve them
mov ah, 0x0e ; tty mode
loop_start: cmp byte [bx], 0 ; compare [bx] which is one byte to zero, for null terminating char je loop_end ; if [bx] == 0, end loop mov al, [bx] ; move char printed to al int 0x10 ; call print interrupt add bx, 1 ; bx + 1, move to next char jmp loop_start ; run loop body again
loop_end: popa ; restore all register ret ; return to callee