Executable Format(可執行檔格式)
Executable Format 主要有:
- Windows 下的 PE(Portable Executable)
- Linux 下的 ELF(Executable Linkable Format)
其他還有 Intel/Microsoft 的 OMF(Object Module Format)、Unix 的 a.out 以及 MS-DOS COM 格式等等。
除了可執行檔外,Dynamic Linking Library 跟 Static Linking Library 都是以 Executable Format 儲存。
ELF 標準中將使用 ELF 格式的檔案分成:
| ELF file type | Example |
|---|---|
| Relocatable File | Linux 的 .o、Windows 的 .obj |
| Executable File | /bin/bash、Windows 的 .exe |
| Shared Object File | Linux 的 .so、Windows 的 .dll |
| Core Dump File | Linux 的 core dump |
ELF file structure
ELF 檔是由 header、一堆 section 及一堆 table 組成的,各 table 也是 section。
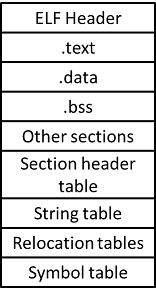
ELF Header
描述整個 ELF 檔的屬性,可用 readelf -h xxx 查看。
struct 定義在 /usr/inclue/elf.h,Elf32_Ehdr or Elf64_Ehdr。
1 | typedef struct |
e_ident 是 magic number 標示這是個 ELF 檔,前 4 個 byte 依序是 0x7f、0x45、0x4c、0x446,接著 3 個 byte 是 “ELF” 三個字母的 ASCII code。所有 ELF 檔前幾個 byte 都是這個內容。除此之外,幾乎所有可執行檔最開始幾個 byte 都是 magic number,供 OS 識別是哪種可執行檔。
e_phoff 表示程式執行時的入口位置,executable file 會填入 address,relocatable file 因為還會進行 relocate 所以值是 0。
從 section header table file offset e_shoff 可以知道 section table 所在位置,由 e_shentsize 及 e_shnum 可以知道 section header table 的 element size 以及總共有多少 element。從 ELF header 可以找到 section header table,由於其他 table 也都是 section,可以再從 section header table 取得所有其他 section 及 table 的資訊。
Section Header Table
描述各 section 的屬性,可用 readelf -S xxx 查看。
一個以 struct Elf32_Shdr(又稱 section descriptor)為 element 的 array,array 的第一個 element 是 NULL,struct 定義在 /usr/include/elf.h。因為 section header table 是個 array,所以 ELF 檔有些地方會以 section 在 section table 中的 index 來 access 或表示該 section。
1 | typedef struct |
如果一個 section 存在 ELF 檔中,由 sh_offset 及 sh_size 可以知道其所在位置及大小。section 屬性主要由 section type sh_type 及 section flags sh_flags 決定。
String Table
.strtab 以及 .shstrtab section。
將 ELF 檔裡所用的字串,如 variable name、function name、section name 等存在一個 array 中,以 '\0' 隔開,並以字串在 array 中的 offset 表示該字串。
Symbol Table
.symtab section,可用 readelf -s xxx 查看。
記錄 object file 所用到的 symbol。每個 symbol 有其對應的 symbol value,variable 及 function 的 symbol value 是它們的 address。
symbol table 是以 struct Elf32_Sym 為 element 的 array,Elf32_Sym 一樣定義在 /usr/include/elf.h。
1 | typedef struct |
對 linking 較重要的兩種 symbol:global symbol 及 external symbol。global symbol 是定義在此 object file 中並且會讓其他 object file 使用到的 symbol,external symbol 則是此 object file reference 到的其他 object file 中的 symbol。簡單講就是給別人用跟用別人的 symbol,有點繞舌。
Relocation tables
存 relocation 的資訊,.rel.text section。每個需要 relocate 的 section 都會有一個 relocation table。
relocation 可參考 Static Link。
Linking View and Execuion View
上述以 section 來劃分 ELF 內容的角度是 Linking View。
ELF 在 mapping 到 virtual address space 時是以 page 為單位,如果 section 的大小不是 page 大小的整數倍又以 section 為單位進行 mapping,會浪費許多 memory。load ELF 時 OS 只在乎 section 的屬性如可讀、可寫、可執行,OS 不在乎 section 的內容,為了節省記憶體空間延伸出「將屬性相同的 section 合併成一個 segment,再對應到 virtual address space」的方式。linker 在 link object file 時會盡量將相同屬性的 section 放在一起。
segment 是以 load 的角度劃分 ELF,也就是 Execution View。