Prefix Scan
prefix scan 是計算一個數值 vector 所有的部份和,每個結果 element 是原始 vector 對應位置之前數值的和,包含自己的稱為 inclusive prefix scan,不包含稱為 exclusive prefix scan。例如 [3, 5, 4, 10, 8] 的 inclusive prefix scan 是 [3, 8, 12, 22, 30],exclusive 是 [0, 3, 8, 12, 22]。
簡單的 sequential 演算法沒什麼好說的,用另一個 array 存結果,一個 loop 加過去:
$ gcc -std=c99 seq.c -o seq
Concurrent Algorithm
將 data 用 thread 數量切成幾塊,每個 thread 負責一塊 data 做區域 prefix scan。取出每一塊區域 prefix scan 最後一個 element 組成一個 array,對這個 array 做 exclusive prefix scan。最後將 exclusive prefix scan 每個 element 加回區域 prefix scan 結果即為整個 array 的 prefix scan。例如:
- 原始資料:
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 9, 8, 7, 6, 5, 4] - 切成四塊:
[1, 2, 3, 4][5, 6, 7, 8][9, 10, 9, 8][7, 6, 5, 4]
- 區域 prefix scan:
[1, 3, 6, 10][5, 11, 18, 26][9, 19, 28, 36][7, 13, 18, 22] - 取出最後一個 element 得到
[10, 26, 36, 22],做 exclusive prefix scan 得到[0, 10, 36, 72] - 將步驟 2 的結果加回對應區塊的區域 prefix scan:
[1, 3, 6, 10][15, 21, 28, 36][45, 55, 64, 72][79, 85, 90, 94],這四塊合在一起就是完整的 prefix scan。
步驟 1 跟 3 各區塊的計算可以獨立完成,步驟 2 需要計算跟 thread 數量相同的 prefix scan,可以用 sequential 的方式處理。這個演算法的步驟 2 必須等步驟 1 全部完成後才能做,步驟 3 也得等步驟 2 做完才能執行,所以實作上要有讓 thread 等待直到某個步驟做完才繼續的機制。
$ gcc -DNUM_THREADS=4 -std=c99 -pthread con.c -o con
實作上用 condition variable 達到「等待上一個步驟做完才繼續」的同步機制。
Performance 比較
sequential 版跟 concurrent 版究竟效能差多少呢?猜想 concurrent 的執行時間會比較短但不會呈倍數減少,例如用 4 個 thread 不會讓執行時間變成 1/4,因為有生 thread 跟同步機制的 overhead。prefix scan 的運算很簡單,concurrent 帶來的 overhead 相對原本計算量的比重會比較高,效能差距可能不會非常明顯。
測試環境
- Debian 9.2
- kernel 4.9.0-4-amd64
- 4 Intel(R) Core(TM) i5-6500 CPU @ 3.20GHz
測量 & 比較
測量結果是用 perf 跑五次得到的執行時間。這是個簡單用來玩玩的例子。
在 input size 固定的情況下觀察 sequential 版本與 concurrent 不同 thread 數的執行時間:
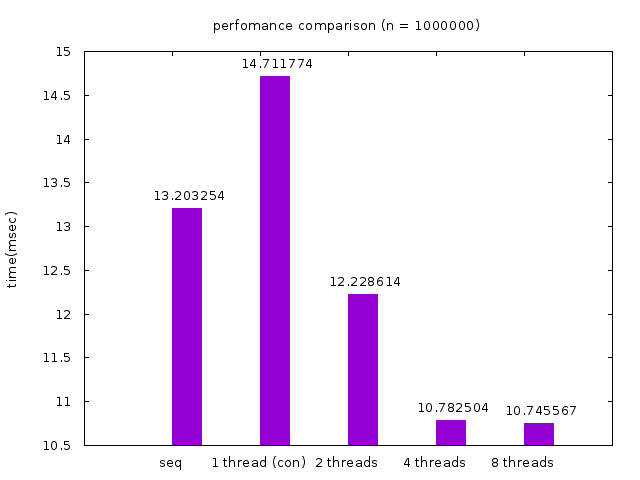
concurrent 版本因為有生 thread 以及 synchronization 的 overhead,在只有一個 thread 的情況下表現會比 sequential 差。兩個 thread 就能比 sequential 好一些,4 個 thread 好更多,但 8 個 thread 的效能沒有再更好。
再比較在不同 input size 下,concurrent 不同 thread 數的相對 sequential 的 speedup(sequential 執行時間 / concurrent 執行時間):
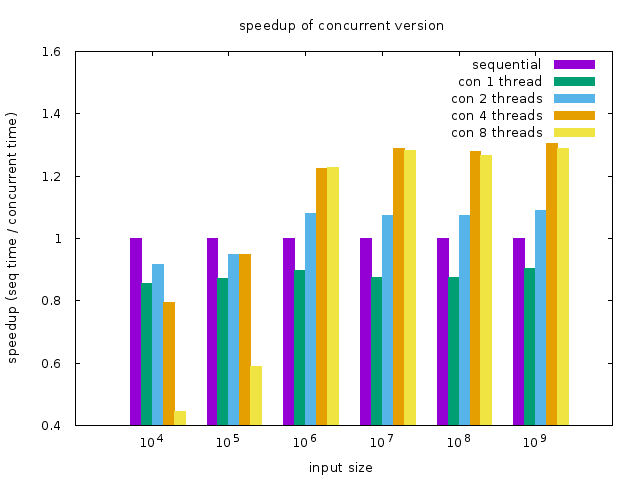
input size 不夠大(10^4 ~ 10^5)concurrent 程式的效能反而因為 overhead 而下降,input size 在 10^6 以上才有明顯的效能提升,但 4 個 thread 跟 8 個 thread 的結果依然差不多。這可能是因為這顆 CPU 是 4 core,超過 4 個 thread 導致 thread 必須在 core 上 context switch 的 overhead。
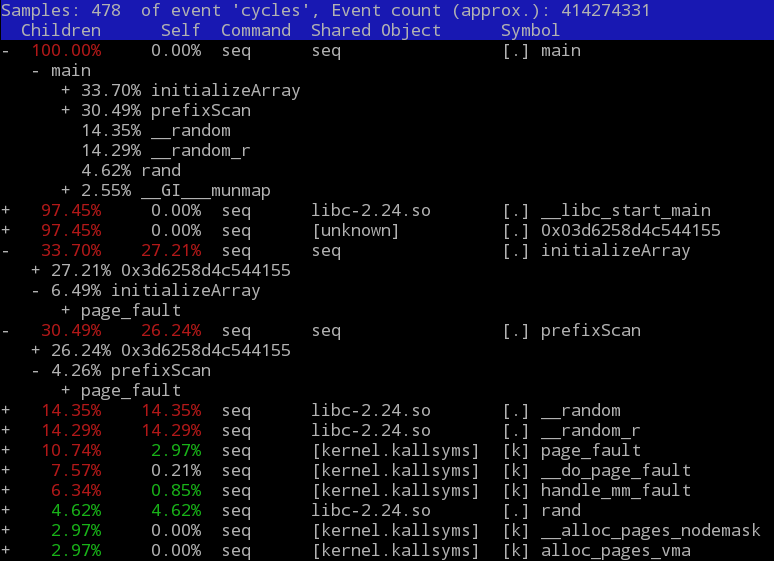
最後看看兩種版本的程式到底都在忙些什麼:
$ perf record -g ./seq 10000000
$ perf record -g ./con_4 10000000
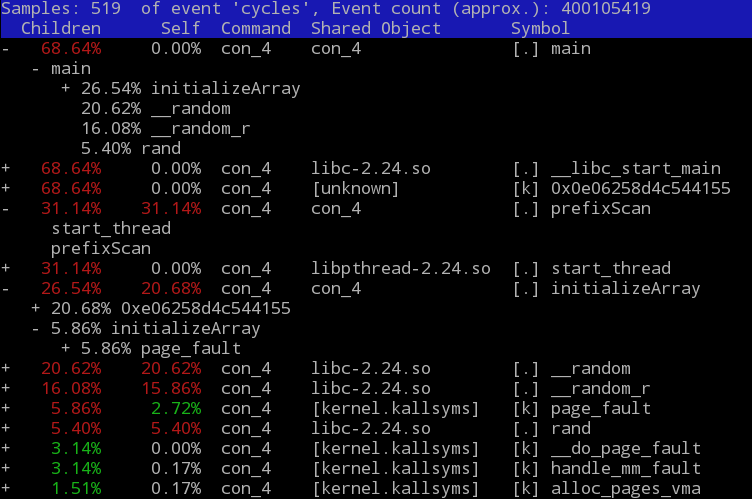
除了計算本身,都花了些時間在亂數產生 input 以及 page fault 上。perf record 產生的報告是 binary 檔,用 perf report 看。
Ref
- 《The Art of Concurrency》
- Linux 效能分析工具: Perf
- perf Tutorial
- Perf – Linux下的系統性能調優工具
- gnuplot 語法解說和示範